Browse categories
Explore
Fiverr Pro
English
$
USD

Level 2
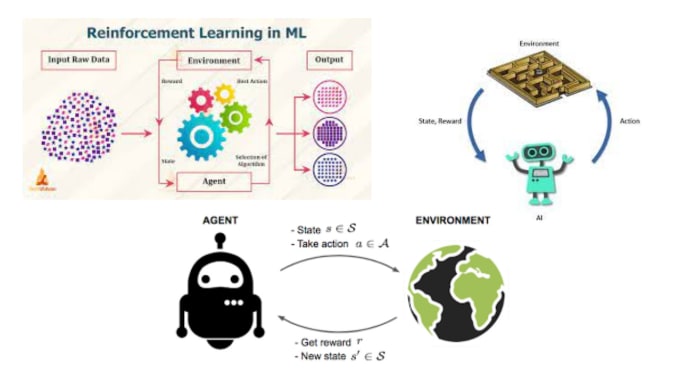

Policy Gradient Agents: Harness the power of Policy Gradient methods, allowing your AI agents to learn optimal policies through gradient ascent. I specialize in designing, training, and fine-tuning these agents for various applications.
Deep Deterministic Policy Gradient (DDPG): Take advantage of DDPG, a state-of-the-art algorithm for continuous action spaces. I can help you implement and optimize DDPG agents for tasks like robotics, control systems, and autonomous vehicles.
Proximal Policy Optimization (PPO): PPO is known for its stability and robustness in RL. I can guide you through the process of using PPO to train agents for complex environments, ensuring rapid convergence and high-performance outcomes.
Actor-Critic Architectures: Employ Actor-Critic methods for both discrete and continuous action spaces. Benefit from the synergy of value function approximation and policy optimization to solve challenging RL problems.
Neural Network Integration: Leverage the power of deep neural networks to enhance the learning capabilities of your RL agents, ensuring they adapt and excel in complex environments.
optimized AI Models
Level 2
Languages
