Browse categories
Explore
Fiverr Pro
English
$
USD
Freelance AI FullStack Developer
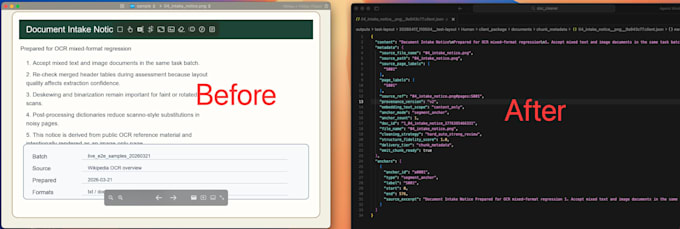
Need clean, reliable document data for your AI workflow?
I help you turn simple documents into RAG-ready outputs for Dify, Make, Coze, and custom pipelines.
What you get
Best for
Supported files
PDF, DOCX, PPTX, TXT, MD, PNG, JPG
Important scope note
This gig is not for advanced layout reconstruction.
If your files have complex merged tables, multi-row headers, or highly complex formatting, message me first for a pre-check.
Integration note
I provide cleaned outputs + guidance/sample usage.
Vector DB ingestion scripts are client-side unless added as a custom order.


Convert from:
Convert to:
JSON
Do you rebuild complex table layouts exactly?
No. This is a text-first, RAG-oriented cleaning service.
Can you handle complex reports with merged cells?
Usually out of scope for this gig. Please contact me first.
Do you integrate into my vector DB directly?
Not by default. I provide outputs + guidance/sample usage.
What about TXT/MD files with no page numbers?
I use stable virtual segment anchors for traceability.