Browse categories
Explore
Fiverr Pro
English
$
USD
Automation, Scraping Django, Flask, Web Dev Frontend InstagramAnalyst
Level 1
Has met certain performance criteria and shows strong potential in the marketplace.
Hi,
Need to extract website data fast and cleanly? I create custom Python web scrapers using BeautifulSoup, Selenium, Playwright and Scrapy for accurate, automated data extraction from any public website.
I provide expert-level Python web scraping and data extraction services using industry-standard tools like:
️ Scraping Tools I Use:
Features & Output:
I only scrape legally accessible and public data sources.
Message me before ordering to discuss your use case I'm ready to help you automate and extract the web data you need.
almohid

What is web scraping and how can it benefit my business?
Web scraping is the automated extraction of data from websites. It enables businesses to collect valuable, structured data for market research, competitor analysis, price monitoring, lead generation, product data aggregation, and trend tracking all without manual effort.
What types of websites can you scrape with Python?
I scrape a wide range of websites, including e-commerce stores, job portals, real estate listings , local business directories, news portals, academic databases, and more. *Note: Always check site permissions before scraping
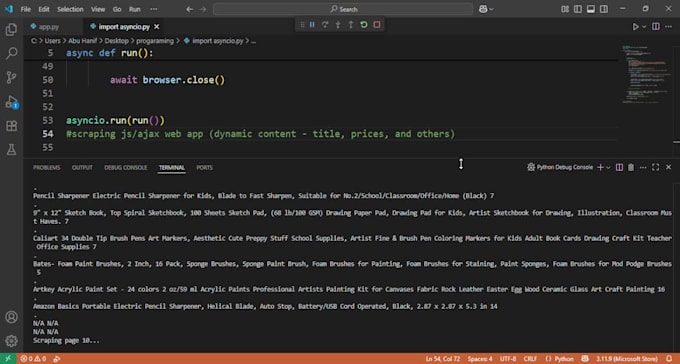
Can you scrape websites that use heavy JavaScript or dynamic loading?
Absolutely! Using Playwright and Selenium, I handle complex web pages with dynamic content loading via AJAX, infinite scroll, or other JavaScript-driven elements, ensuring no data is missed.
How do you handle websites that require login or session authentication?
I automate secure login processes using Playwright or Selenium, managing cookies and session tokens to extract data behind login walls fully compliant with website terms and conditions.
What data formats can I get my scraped data in?
I deliver clean, validated data in formats such as CSV, Excel, JSON, XML, SQL databases, or Google Sheets, tailored to your preferred workflow or system integration needs
Do you provide the scraping scripts and automation code?
yes! Upon request, I share fully commented, reusable Python scripts built with Playwright, Selenium, or Scrapy empowering you to run or customize the scraper independently.
Can you set up scheduled and automated scraping jobs?
Definitely. I configure cron jobs, cloud functions, or serverless scrapers to run automatically on custom intervals —daily, weekly, or monthly —for continuous data refresh
How do you manage anti-scraping protections and bot detection?
I implement advanced techniques including user-agent rotation, proxy usage, stealth browser modes (especially with Playwright), request throttling, and CAPTCHA handling (where permitted) to bypass common anti-bot measures ethically.
How quickly can I expect my scraped data?
Turnaround depends on complexity: simple scraping tasks usually take 1-3 days; multi-page or large-scale crawling projects take 3-7 days. I provide clear, transparent timelines before starting.