Browse categories
Explore
Fiverr Pro
English
$
USD
Data extraction from PDFs, government portals and scanned documents
Got a PDF full of data you cannot use? I will turn it into a clean, structured spreadsheet.
I specialise in the hard cases - scanned documents, image-based PDFs, government filings, financial reports, invoices, and any source that resists copy-paste.
What you get:
My tools: Python, pandas, AI-powered OCR, modern AI tooling
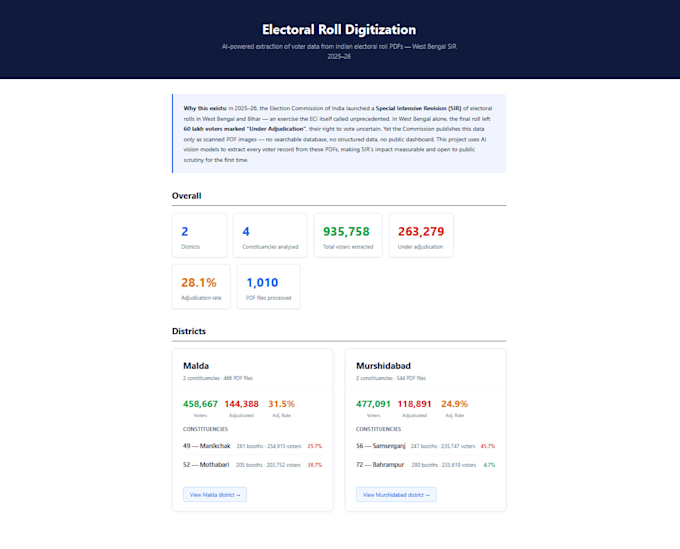
My track record: I extracted 1.28 million records from scanned electoral roll PDFs for AltNews, one of India's top fact-checking organisations. If I can extract voter data from image-only government documents behind CAPTCHAs, I can handle your PDFs.
Send me a sample PDF before ordering - I will tell you exactly what I can deliver and how fast.

Technology:
Python
•
Excel
•
Selenium
•
Beautiful soup
•
Pandas
Technique:
Automated
What kinds of PDFs can you handle?
Native PDFs, scanned image-only PDFs, government documents, financial reports, invoices, and lists. If text or numbers are visible to the eye, I can extract them. Send a sample first and I will confirm fit and timeline within a day.
What format will I get the data in?
Excel (.xlsx), CSV, or Google Sheets - your pick. I can also deliver JSON for structured or nested data. Tell me your preference when you order, or I will default to clean Excel with one tab per source.
Do you handle non-English PDFs?
Yes. I have particular experience with Hindi and Bengali documents, including scanned ones. Most Latin-script languages also work well. If your source is in a different script (Arabic, Tamil, etc.), send a sample first - I will confirm capability before you order.