Browse categories
Explore
Fiverr Pro
English
$
USD
About This Gig
I specialize in building multi-modal speech and emotion recognition systems by combining audio and text modalities for enhanced performance and accuracy.
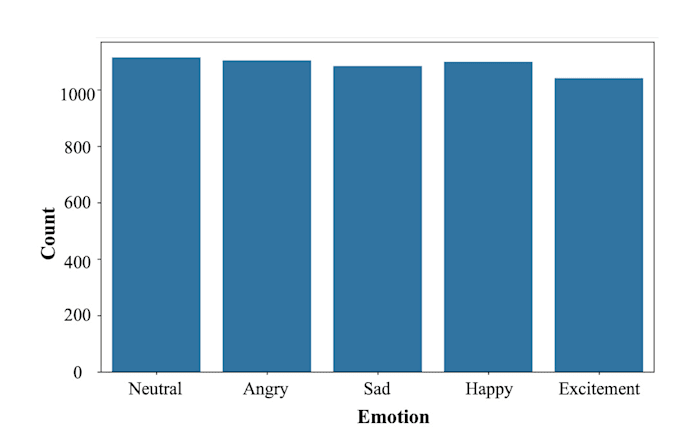
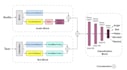
With hands-on experience working on complex datasets like IEMOCAP and MELD, I have developed custom hybrid models using Bi-LSTM and CNN, achieving up to 85% accuracy on the IEMOCAP dataset. I'm also actively exploring Word2Vec and Transformer-based architectures for improved contextual understanding in speech.
You can check out my projects and research papers linked below for more details.
What I Offer:
Feel free to message me before placing your order to discuss your specific needs.

Expertise:
Classification
•
Speech & Audio
•
Predictive analysis
Programming language:
Python
•
Colab
APIs:
Other
Tools:
Jupyter Notebook
•
Amazon SageMaker
•
Colab
Frameworks:
Scikit-learn
•
Keras
•
PyTorch
•
Panda
•
TensorFlow