Browse categories
Explore
Fiverr Pro
English
$
USD

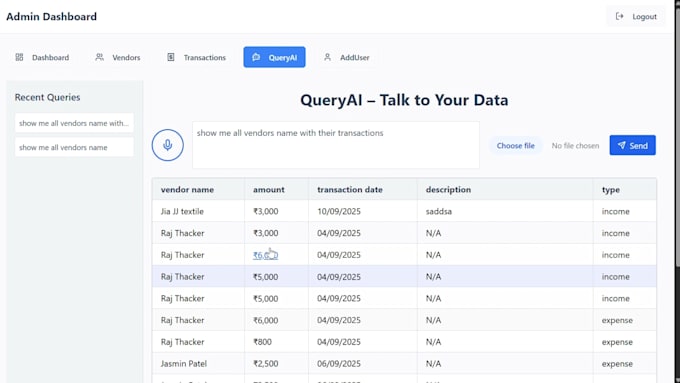
Need to automate extracting information from documents instead of doing manual copy-paste work? I build Python-based automation solutions that process files quickly, accurately, and at scale.
I have experience building document-processing workflows for financial reporting, invoice handling, workpaper automation, and structured data pipelines.
What I can help with:
Extract data from invoices, receipts, forms, and financial documents
Process tables and structured information from complex files
Handle multi-page documents and scanned files using OCR
Convert extracted information into JSON, CSV, Excel, or database-ready formats
Build automation scripts or API-based workflows for integration into existing systems
Tech stack: Python · pdfplumber · PyMuPDF · OCR · FastAPI · SQL
Deliverables include clean code, setup instructions, documentation, and sample outputs for testing.
Please message me with a sample file and expected output format before ordering so I can confirm scope and feasibility.
Python Backend Developer with FastAPI REST APIs and AI Integration
Languages
Can you handle scanned PDFs?
Yes, I use OCR (Tesseract/AWS Textract) for scanned documents.
What format will the output be in?
JSON, CSV, or directly into your database — your choice.
Can you process PDFs automatically on a schedule?
Yes, I can build an automated pipeline on the Standard or Premium package.