Browse categories
Explore
Fiverr Pro
English
$
USD



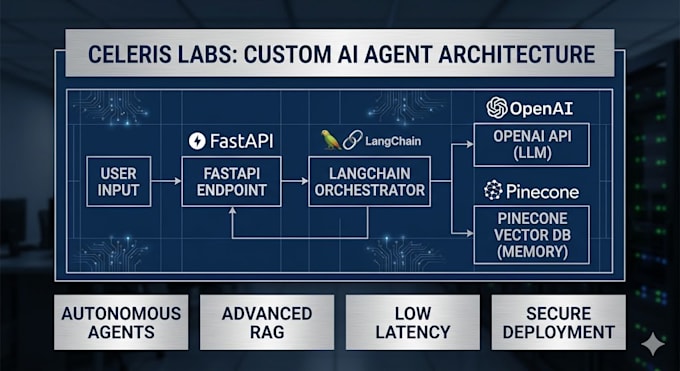
Scalable AI Agents & Full-Stack Solutions by Celeris Labs
Most "AI experts" just give you a simple prompt. At Celeris Labs, we build production-ready intelligence. We specialize in the LangChain + FastAPI + Pinecone stack to deliver agents that don't just chatthey execute.
What We Build:
Why Celeris Labs?
We are an execution-focused foundry. We prioritize latency, security, and clean architecture. Whether you are a startup looking for an MVP or an enterprise automating a workflow, we bridge the gap between AI theory and real-world software.
Lets engineer your edge. Send a message to discuss your architecture before ordering.
Custom AI Solutions and Full Stack Engineering
Languages
Do you provide the full source code and documentation?
Yes. For our Standard and Premium tiers, Celeris Labs provides complete ownership of the source code, including detailed documentation and deployment instructions so you can scale the system internally.
Can the AI agent access my private business data securely?
Absolutely. We specialize in RAG (Retrieval-Augmented Generation) using Pinecone vector databases. This allows your agent to answer questions based strictly on your private documents without training the model on your sensitive data, ensuring both accuracy and security.
Which AI models do you support?
We are model-agnostic. While we primarily use GPT-4o for its reasoning capabilities, we also build with Claude 3.5 Sonnet, Gemini Pro, and open-source models like Llama 3, depending on your project's specific needs for latency and cost.