Browse categories
Explore
Fiverr Pro
English
$
USD


️ Next-Generation AI Voice Agents by Celeris Labs
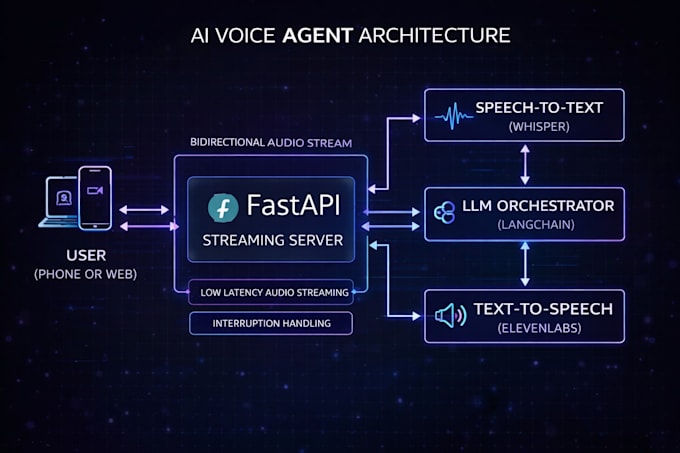
Text-based chatbots are standard, but voice AI is the future. Celeris Labs engineers highly responsive, ultra-realistic conversational voice agents that can speak to your users on the web, or even make and receive actual phone calls.
What We Build:
The Tech Stack:
We deploy using Python, FastAPI, LangChain, Whisper, and ElevenLabs/Twilio, ensuring the audio streams with absolute minimal latency.
Message us before ordering so we can discuss your specific use case and audio requirements!
Custom AI Solutions and Full Stack Engineering
Languages
Can you clone a specific voice for my AI agent?
Yes. If you provide a clean, high-quality audio sample (at least 1-2 minutes with no background noise), we can use ElevenLabs to clone that specific voice for your application.
Can the AI agent actually call my customers on their phones?
Yes! For the Premium package, we integrate the AI with telecom APIs like Twilio. This allows the bot to make outbound calls or receive inbound calls using a dedicated phone number.
What about lag/latency? Will there be an awkward pause before the AI speaks?
We heavily optimize for latency. By using FastAPI and streaming audio chunks directly from the provider (like ElevenLabs) instead of waiting for the full sentence to generate, we keep response times as close to human-level as possible.