Browse categories
Explore
Fiverr Pro
English
$
USD





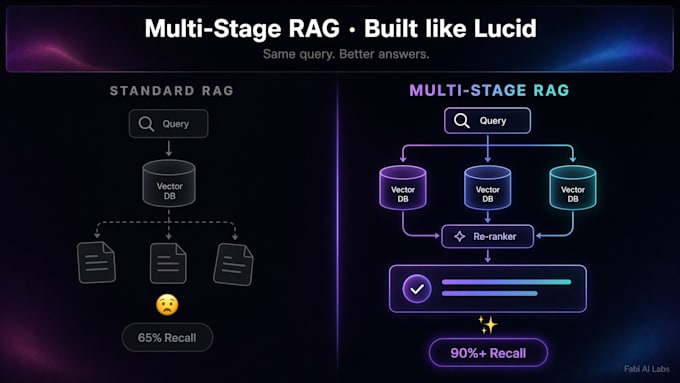
Standard RAG hits a wall at compound questions. A single-query bot retrieves chunks mentioning "refund" and misses nuance - pricing rules, damage clauses, custom-order policies.
Multi-stage RAG is different. It decomposes into sub-queries, retrieves in parallel, re-ranks, and synthesizes. Recall jumps from 65% to 90%+. Answers stay grounded. Hallucinations drop.
WHAT YOU GET:
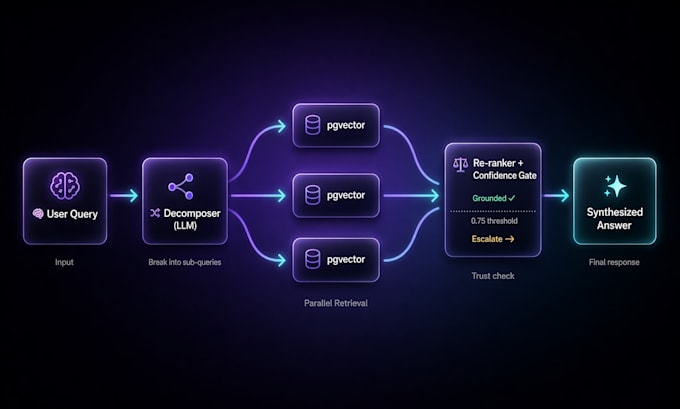
- Query decomposition (LLM breaks compound questions into targeted searches)
- HyDE hypothetical document embedding for retrieval
- Re-ranking + confidence scoring before answer generation
- 4 safeguards: human handoff, uncertainty gate, no gaslighting, transparency
- Custom eval test set with measurable retrieval quality
- Admin dashboard for conversation + retrieval debugging (Premium)
STACK: Python/TypeScript, Supabase pgvector, OpenAI/Anthropic/Gemini APIs, custom re-ranker.
WHY MULTI-STAGE: single-query RAG works for simple FAQs. If your bot handles pricing nuance or compound questions - you need this.
This is what I built into Lucid. Same architecture for your domain, tuned to your voice.
Send me your use case plus 10 hard questions your current bot can't answer. I'll reply with scope.
AI Developer and Creator of Lucid
Languages
How is multi-stage RAG different from basic RAG?
Basic RAG runs one vector search per question. For compound questions, single-search recall is ~65%. Multi-stage RAG decomposes the question, searches in parallel, re-ranks. Recall jumps to 90%+. Fewer hallucinations, better grounded answers.
Will this cost more than basic RAG at scale?
Often less. Decomposition uses cheap models (Gemini Flash at ~$0.10 per 1M tokens). Final answer uses one premium model call. Basic RAG pays premium for every call. At 10k+ conversations/month, multi-stage frequently runs 30-50% cheaper.
What if my docs are messy or unstructured?
Handled as part of scope. I normalize docs during ingestion - chunking by semantic boundaries (not naive paragraph splits), cleaning boilerplate, adding metadata for filter-based retrieval. Messy input is the default assumption, not an exception.
Do I still bring my own API keys?
Yes - same policy as my Starter Bot gig. You own the OpenAI / Anthropic / Gemini accounts, pay direct pricing with no markup, keep full control. I help pick the most cost-efficient model mix for your traffic volume.