Browse categories
Explore
Fiverr Pro
English
$
USD


Stop Burning Money on Redundant AI Calls!
Most AI apps waste 40% to 80% of their budget on redundant LLM calls. Im here to help you stop the bleed.
I will build a Production-Ready Semantic Cache that "remembers" past queries and serves answers instantlyslashing your costs and making your app feel lightning-fast.
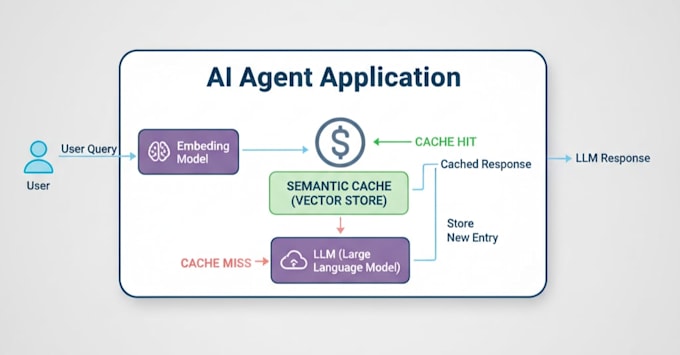
What is Semantic Caching?
Standard caching is "dumb"it needs a 100% word-for-word match. Semantic Caching is smart. Using Vector Embeddings, your system will understand intent. If User A asks "How's the weather?" and User B asks "What's the forecast?", the system knows theyre the same. It serves the stored answer instantly without hitting your API.
️ Whats included in this Gig?
Code, Scrape, Automate, FullStack Developer for Data and AI
Languages
Won't caching make the AI give "old" or "wrong" information?
Not if it's done right. We implement "Cache Invalidation" and "Time-to-Live" (TTL) settings. If your data changes frequently, we can set the cache to expire every hour. If it's static data, it can last forever. We also tune the "Similarity Threshold" so only truly similar questions trigger a cache h
How much money will I actually save?
This depends on your "Cache Hit Rate." For customer support bots or FAQs, users often ask similar questions, leading to 60-90% savings. For highly creative or unique task bots, savings usually hover around 20-30%.
Is my data secure?
Completely. The cache is hosted on your infrastructure (or your preferred cloud database). I do not store your data on my own servers.
Does this work with any LLM?
Yes. Whether you are using OpenAI’s GPT-4o, Google Gemini 1.5, Claude 3.5, or even local models like Llama 3, the caching layer sits in front of the API, making it provider-agnostic.