Browse categories
Explore
Fiverr Pro
English
$
USD




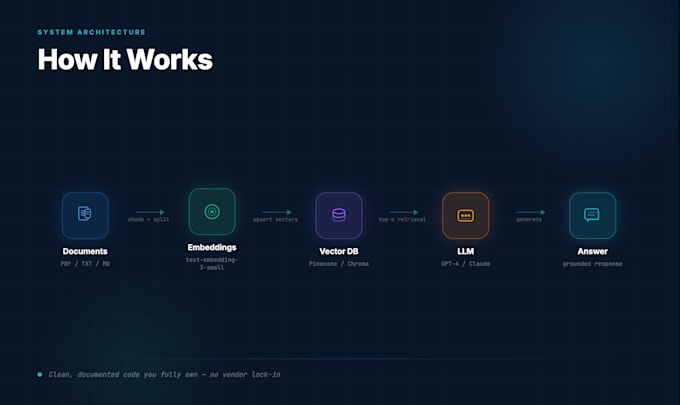
Looking to build a RAG (Retrieval-Augmented Generation) system over your documents, knowledge base, or website? You're in the right place.
I'm an AI Engineer with 2 published research papers (IJCNIS, IRJET) and production experience shipping LLM systems at Sambhav AI, where I delivered 50% performance gains. I build RAG pipelines that actually work in production not fragile notebook demos.
What you get:
Clean document ingestion (PDF, DOCX, web, APIs) Vector embeddings with OpenAI or HuggingFace models ChromaDB or Pinecone as your vector store LangChain orchestration with memory and re-ranking Integration with GPT-4o, Claude, or Gemini Clean, documented Python code you own
Why me:
Published in IJCNIS (Deep Learning for Skin Cancer) and IRJET (Job Search ML) Shipped production Whisper + OCR pipelines at Sambhav AI 50% faster Built DevBridge (AI documentation generator 65% time saved) GitHub: github.com/harshaldonarkar Portfolio: harshaldonarkar.github.io
Please message me before ordering so I can confirm feasibility and recommend the right package for your data volume and use case.
AI Engineer: RAG Pipelines and LLM Integration Expert
Languages
Do I need my own API keys?
OpenAI or Anthropic API keys. I'll guide the setup if needed.
What data formats do you support?
PDF, DOCX, TXT, CSV, web pages, APIs, SQL databases.
Can you deploy it on my server?
Yes — the Premium package includes Docker deployment with full documentation.
Will I get the source code?
Always. Clean, commented Python with a README.
What if my documents are in Hindi / other languages?
Yes — I build multilingual RAG using multilingual embedding models.