Browse categories
Explore
Fiverr Pro
English
$
USD
Senior Data Engineer ,Spark ,Scala ,AWS ,Airflow , Kafka ,Big Dat
Are you looking for a reliable PySpark Data Engineer to build or optimize your ETL pipelines?
You're in the right place.
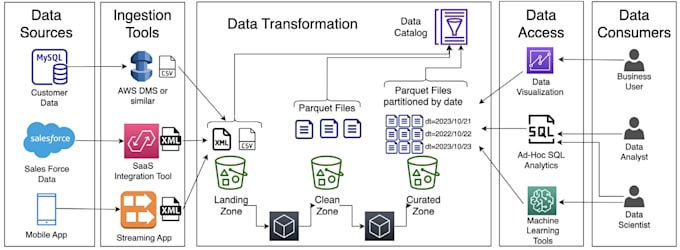
I'm Pankaj, a Data Engineer with 3+ years of experience at Paytm, where I built 200+ production ETL pipelines processing over 5 TB/day using PySpark, Airflow, AWS, and Kafka.
This gig focuses 100% on delivering fast, scalable, and clean PySpark ETL solutions for your business.
What I Can Do for You
Why Choose Me
Technologies I Use
Have a custom requirement?
Message me anytime I reply fast.
Lets build something scalable.

What do you need from me to start?
Database/API access, sample data, SQL logic, or problem statement.
Can you connect to my database or API?
Yes — MySQL, PostgreSQL, MongoDB, APIs, S3, and more.
Do you optimize existing pipelines?
Yes — I specialize in runtime optimization and debugging.
Can you integrate AWS services?
Yes — Glue, S3, EMR, Lambda, Athena.
Can you sign an NDA?
Yes — I can work under NDA if required.