Browse categories
Explore
Fiverr Pro
English
$
USD
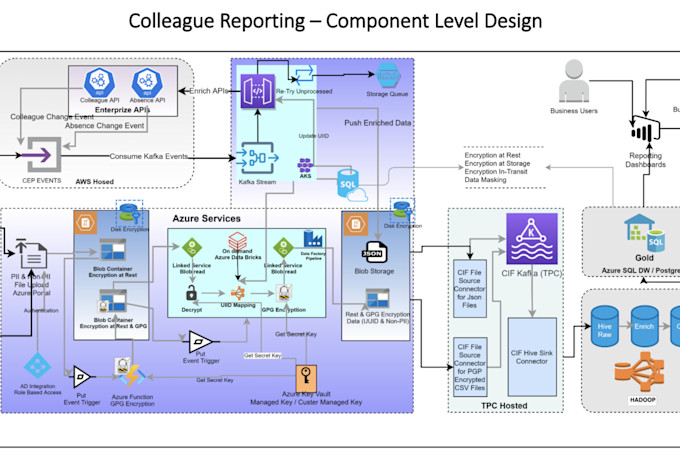
Senior Data Engineer: AWS, Azure, Spark, ETL Pipelines and Data Architecture
Struggling with slow or unreliable data pipelines? I design and build production-grade ETL pipelines on AWS and Azure that are fast, scalable, and built to last.
What You'll Get:
- End-to-end ETL pipeline design and implementation
- Apache Spark performance optimization (PySpark, Scala)
- AWS setup: Glue, Lambda, Step Functions, S3, Redshift
- Azure setup: Databricks, Data Factory, Azure Data Lake Gen2
- Data validation, error handling, and monitoring
- Full documentation and handover
Ideal For:
- Businesses with slow or failing data pipelines
- Teams migrating from on-prem to AWS or Azure
- Projects needing Spark optimization and tuning
- Real-time or batch ETL development
Why Choose Me:
5+ years building enterprise data pipelines across retail, IoT, and finance industries. I have handled pipelines processing millions of records daily and will bring that same expertise to your project.



Destination Platform:
Amazon Redshift
•
Amazon S3
Tools & Platforms:
AWS Glue DataBrew