Browse categories
Explore
Fiverr Pro
English
$
USD
专业的网页爬虫与数据分析为您的企业服务
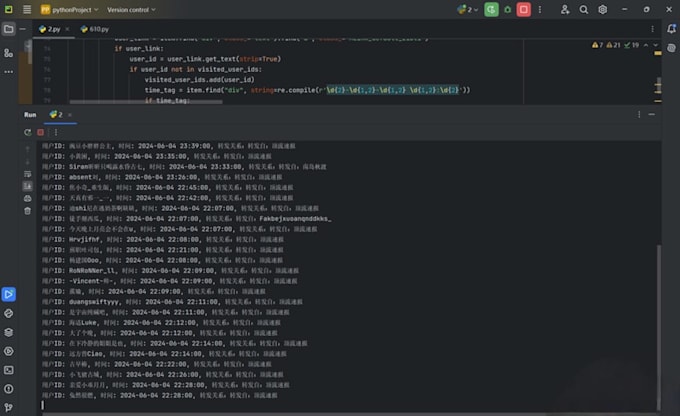
需要网站数据但厌倦了复制粘贴?我会为你打造一个定制的网页爬虫,把凌乱的页面变成干净、可操作的电子表格或报告。
我提供的是:
·抓取静态或动态页面(JavaScript/AJAX)
·登录、分页和验证码处理
·数据清理、重复去重和格式化
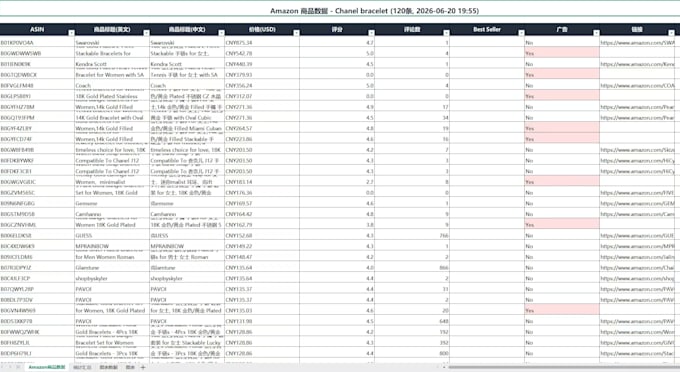
·以 CSV、Excel 或可视化的 PDF 报告形式交付
·用于定期提取的自动化脚本
我的工具箱:蟒蛇、Scrapy、硒、熊猫、剧作家,等等。
所有工作均依据robots.txt和法律规范进行。我乐于处理从小型一次性清单到大规模采矿项目的各种事务。
请查看我的三个包裹,或者发消息获取定制优惠。让我们今天就获取您的数据吧!
---


Technology:
Python
•
Scrapy
•
Selenium
•
Playwright
•
Pandas
Technique:
Manual
Q: Is web scraping legal? Do you follow website rules?
A: Yes, I strictly follow robots.txt and only scrape publicly accessible data. I do not engage in any illegal activity or breach of terms of service.
Q: What if my target website has a login or CAPTCHA?
A: I can handle many login-based sites and CAPTCHAs. Please message me the details before ordering so I can confirm feasibility and may add a small extra fee.
Q: What format will I receive my data in?
A: By default, you get a clean CSV or Excel file. Premium packages also include a visualized PDF report with charts and insights.
Q: How long does delivery take?
A: Basic packages are delivered within 2–3 days, Standard within 4–5 days. For large or complex projects, I’ll confirm the timeline before you order. Express delivery is also available as an extra.
Q: Can you scrape a large number of pages, like 500 or more?
A: Absolutely. For very large projects, please contact me first so I can provide a custom quote and timeline.
Q: I have a custom requirement not listed in your packages. What should I do?
A: Simply send me a message! I’m happy to create a custom offer tailored exactly to your needs.