Browse categories
Explore
Fiverr Pro
English
$
USD




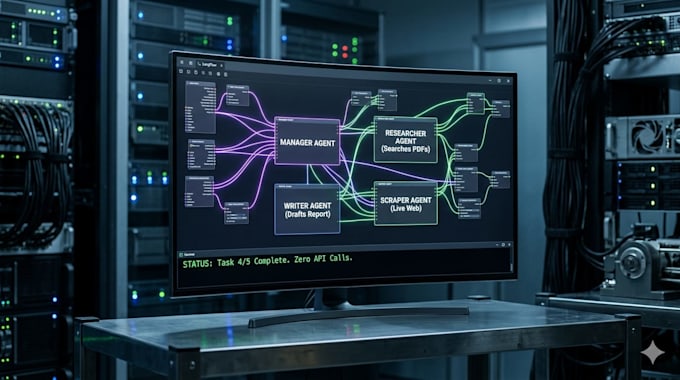
I build Sovereign AI Infrastructureprivate, local, and high-performance systems that run on your own hardware with Zero API costs.
As a Systems Architect, I specialize in deploying Large Language Models (LLMs) and autonomous agents that prioritize Data Sovereignty and Privacy. Whether you need a private research assistant or a complex multi-agent workflow, I deliver clean, production-ready code optimized for local execution.
What I Offer:
The Deliverable: Every project includes full Source Code, a Dockerized environment for one-click setup, and professional documentation. No gatekeepingyou own the system I build.
Stop paying for tokens. Build your fortress.
Local Intelligence, Total Privacy, Expert AI Solutions
Languages
what exactly is "Sovereign Ai" and why do i need it?
Sovereign AI means owning your intelligence instead of renting it. I build systems that run on your hardware or private cloud. No data leaves your network, and you pay zero monthly API fees. It is total control over your data and your digital future.
Do i need a $10,000 server to run Local LLMs?
No. Using quantization (GGUF/EXL2), I optimize models like Llama 3 to run on consumer hardware. An RTX 3060/4060/5060 with 8GB VRAM is plenty for a high-speed private assistant. I specialize in making "heavy" models run on lean, efficient machines.
Can the Ai securely read my private company documents?
Yes. I use RAG (Retrieval-Augmented Generation) to create a local "Vector Database." The AI searches your PDFs, CSVs, or SQL files in real-time. Your data never touches the internet and is never used to train public models. It remains 100% private.
what is the difference between RAG and Fine-Tuning?
RAG is like an "open-book exam"—the AI looks up facts in your data. Fine-tuning is "brain surgery"—it changes the AI’s personality or specialized jargon. RAG is best for accuracy; Fine-tuning is best for a unique voice. I provide both to ensure total system synergy.
Is this cheaper than paying for ChatGPT Plus or APIs?
Long-term, absolutely. While there is an upfront cost, your "per-message" cost becomes $0.00. For high-volume businesses, a sovereign setup usually pays for itself in 3-6 months by eliminating recurring subscription traps and vendor lock-in.
How do you deliver the final product?
I provide a "Sovereign Container" via Docker. No complex installs or driver headaches. You get a one-click setup script and a professional README. Run the script, and the AI launches in your browser as a private, secure web app.
will you help me with the initial setup?
Every package includes a detailed guide. For Standard and Premium tiers, I offer a 1-on-1 remote session to optimize your environment for your specific GPU and VRAM, ensuring you get the highest tokens-per-second performance possible.