Browse categories
Explore
Fiverr Pro
English
$
USD




6+ years of Python experience. 10+ scraping pipelines delivered across enterprise clients.
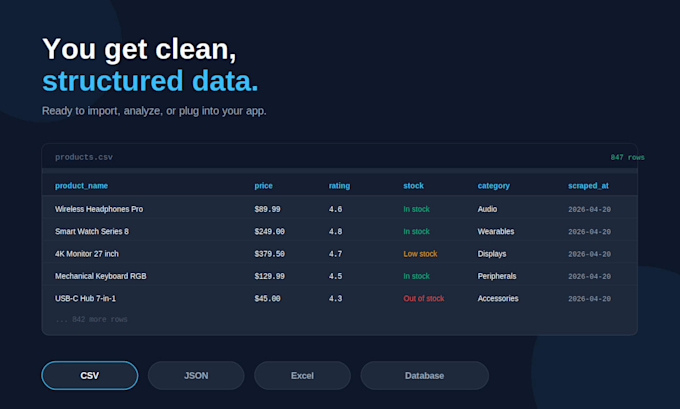
I'll extract the data you need from e-commerce sites, directories, social media, real estate listings, whatever and deliver it clean and structured.
Tools I use:
You get:
Please message me with the target URL before ordering I need to check feasibility (some sites are heavily protected).
Full Stack Developer
Languages
What do I receive at the end?
You'll get a clean Python script you can run yourself on your computer or server, plus the extracted data in your preferred format (CSV, JSON, Excel, or directly in a database). I include clear documentation so you can run it, modify it, or schedule it without my help.
What happens if the website changes and the scraper breaks?
Websites change over time, which can break any scraper. Minor fixes within 14 days of delivery are free. For major site redesigns or long-term maintenance, I offer affordable monthly maintenance packages, just message me to discuss.
What if I need more than 100 pages?
No problem, my packages include up to 100 pages, and you can add the "Additional pages mined/scraped" extra to scrape as many as you need. Large-scale projects (50,000+ pages) are also possible, message me for a custom quote.
Do you handle login-protected or dynamic JavaScript sites?
Yes. I use Selenium and Playwright for JavaScript-heavy sites (infinite scroll, dynamic content, AJAX-loaded data). For login-protected sites, I can work with your credentials if the scraping is for your own account or authorized use, never for bypassing access controls on sites you don't own.