Browse categories
Explore
Fiverr Pro
English
$
USD
With hard work and effort, you can achieve anything
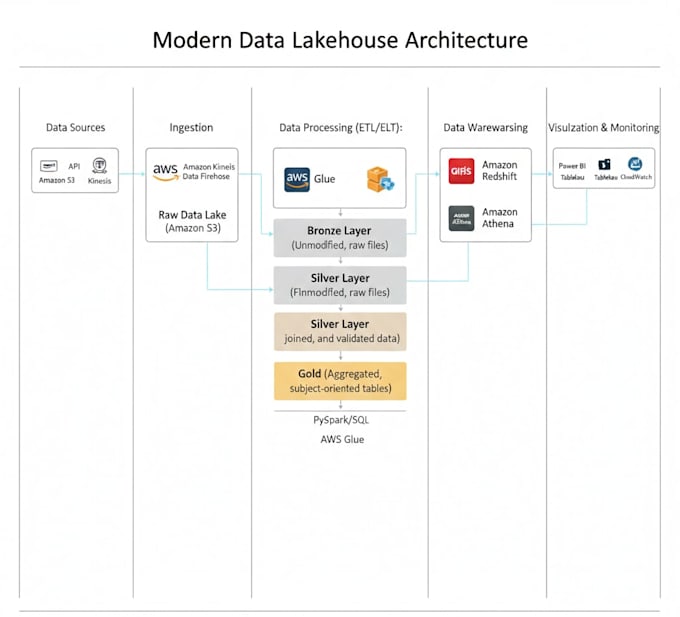
Are you looking for a technical expert to architect your cloud infrastructure and develop high-performance ETL/ELT pipelines? You are in the right place.
I specialize in designing and deploying end-to-end data solutions. Whether you need a modern Data Lakehouse on Azure, a robust pipeline on AWS, or complex transformations in Databricks, I deliver production-ready architectures.
My Expertise & Services:
The Tech Stack:

Expertise:
API integration
•
Big data
•
Data extraction
•
ETL
•
SQL
•
NoSQL
Will you explain the implementation architecture as well?
Yes, I provide a complete walkthrough of the architecture. I will explain the data flow, the choice of specific cloud services (ADF, Databricks, etc.), and the reasoning behind the design to ensure your team can manage it moving forward.
Can you handle both small-scale and large-scale data projects?
Absolutely. I design pipelines with scalability in mind. Whether you are a startup needing a simple API-to-SQL ingest or a large organization processing billions of rows via Spark, I tailor the compute and storage to fit your specific volume and budget.
Do you provide technical documentation with the delivery?
Every project includes a technical overview and setup guide. For enterprise-grade, detailed documentation (including data dictionaries and mapping documents), please mention this during our discovery call so I can include it in the project scope.
Do you provide ongoing support for the solutions you develop?
Yes. I offer post-delivery support to ensure the pipeline runs smoothly in production. This includes troubleshooting initial runs, bug fixes, and performance tuning. Longer-term maintenance or monthly support can also be arranged.
How do you determine the pricing for a project?
Pricing is based on three factors: the number of data sources, the complexity of the transformations (ETL/ELT logic), and the orchestration requirements. I provide a transparent quote after reviewing your data schema and project goals.
What is the approach to getting started with a project?
We start with a brief discovery phase where I review your data sources and destination requirements. Once the architecture is approved, I set up the environment, build the pipelines, perform rigorous data validation, and finally hand over the code with a technical walkthrough.