Professional Data Engineering Services | ETL Pipelines | AWS | Databricks
Are you looking to build scalable, reliable data pipelines for your business?
I am a Data Engineer with 6+ years of experience designing and optimizing ETL pipelines using modern cloud and big data technologies.
What I can do for you:
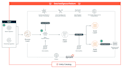
- Build end-to-end ETL pipelines (Extract, Transform, Load)
- Develop PySpark / Spark jobs for large-scale data processing
- Design data lakes on AWS S3
- Create workflows using Apache Airflow
- Implement Databricks solutions for analytics and ML
- Optimize pipelines for performance and cost efficiency
- Integrate data from APIs, databases, and files (CSV, JSON, Parquet)
️ Tech Stack:
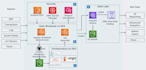
- AWS: S3, Glue, IAM, CloudWatch
- Databricks
- Apache Spark / PySpark
- Apache Airflow
- Python / SQL
Why choose me?
- Built pipelines handling multi-terabyte datasets
- Strong focus on performance optimization
- Clean, maintainable, production-ready code
- Fast communication & reliable delivery
Example Use Cases:
- Data warehouse pipelines
- Data lake architecture
- Batch & scheduled workflows
- Data cleaning & transformation
- API to S3 ingestion pipelines