Browse categories
Explore
Fiverr Pro
English
$
USD



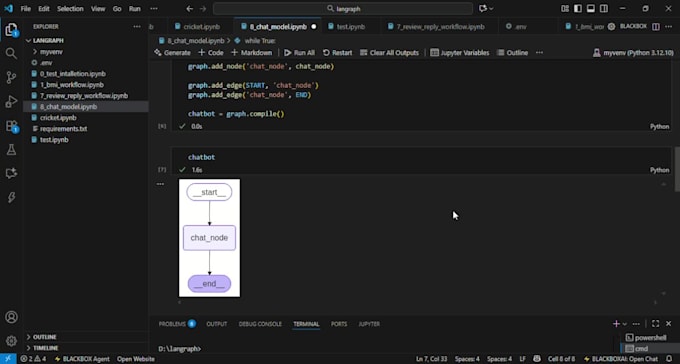
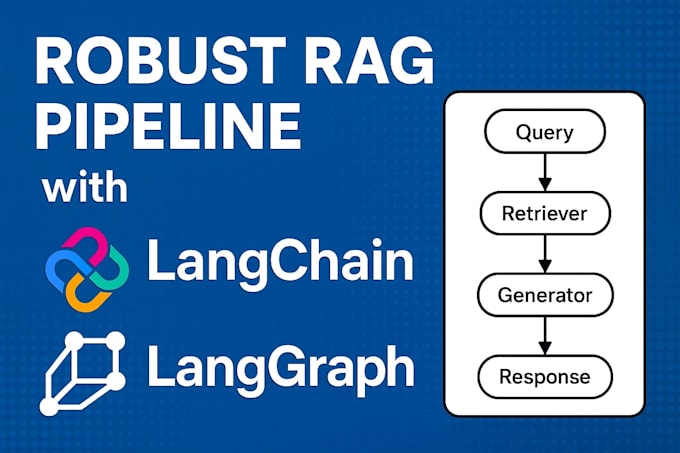
I design and build robust Retrieval-Augmented Generation (RAG) pipelines that deliver accurate, context-aware answers from your own data sources.
No hallucinations. No brittle scripts. Just production-grade architectures clean, modular, and fully documented.
️ What You Get
Why Work With Me
Tech Stack: Python · LangChain · LlamaIndex · Hugging Face · FAIS· Chroma · OpenAI API · Streamlit · FastAPI
Lets discuss your data sources and desired deployment stack
Machine Learning, Deep learning, Gen AI and Agentic AI
Languages
Can I use my own data (PDFs, Notion, Google Drive)?
Absolutely. I can set up connectors for your local or cloud-based data sources.
Will I get the full source code?
es. All code and environment files are included and documented.
Can you integrate with my existing app or API?
Yes — I can wrap the RAG pipeline with FastAPI endpoints or embed it in your frontend.