Browse categories
Explore
Fiverr Pro
English
$
USD
Data analytics
Level 1
Has met certain performance criteria and shows strong potential in the marketplace.
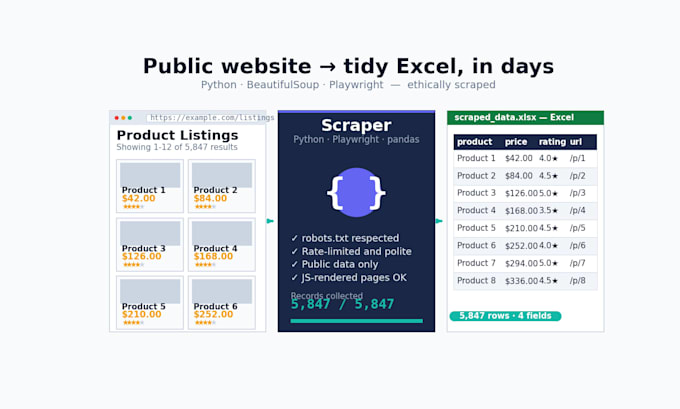
Send me URLs and the fields you need I'll build a Python scraper and deliver the data as a clean Excel or CSV file, ready for analysis.
What you get:
- A clean .xlsx or .csv with one row per record, normalized field names
- Source URL column for every row (so you can audit any data point)
- Type-fixed values (numbers, dates, currencies)
- Light deduplication and validation
- Optional: the reusable Python scraper script with a README (Premium)
I scrape:
- E-commerce product pages (Amazon, Shopify stores, niche retailers within their TOS)
- Real-estate and rental listings
- Job boards (public job postings)
- Directory sites (yellow pages, business listings)
- Government and regulatory portals
- Public review sites
- Public sports / stats sites
- News headlines and article metadata
Both static HTML sites and JavaScript-heavy sites are handled (Selenium / Playwright when needed).
What I won't do (please don't ask these violate platform TOS or law):
- Scrape sites that require login (LinkedIn, Facebook, Instagram, X/Twitter, gated forums, paid databases)
- Bypass CAPTCHAs or anti-bot systems beyond reasonable rate-limiting
- Scrape personal data in ways that violate GDPR / CCPA


Technology:
Google Sheets
Expertise:
API integration
•
Data extraction
•
Data flow
What does the basic package include?
(1) Up to 500 records; (2) Single static-HTML site; (3) Up to 8 fields per record; (4) Clean .csv or .xlsx output
What does the standard package include?
(1) Up to 5,000 records; (2) Multi-page or paginated sites; (3) JavaScript-rendered content (Selenium / Playwright); (4) Up to 15 fields per record; (5) Light deduplication + type fixing; (6) Clean .xlsx output
What does the premium package include?
(1) Up to 50,000 records; (2) JS-heavy sites, complex pagination, infinite-scroll handling; (3) Up to 30 fields per record; (4) Full data cleaning + validation; (5) Reusable Python scraper script with README so you can re-run on demand; (6) Run instructions for scheduling (cron / GitHub Actions / cl
Is web scraping legal?
Scraping publicly accessible data is generally legal in most jurisdictions, but the law varies. Each site's terms of service may impose additional restrictions. I scrape only public data, respect `robots.txt`, and refuse jobs that violate site TOS or platform policies. You're responsible for confirm
Can you scrape LinkedIn / Facebook / Instagram / X?
No. These platforms explicitly prohibit scraping in their TOS and have litigated against it. Don't ask — the gig will be cancelled.
Can you scrape behind a login I provide?
No. Even with your credentials, automated access typically violates the site's TOS. There are narrow exceptions for sites you own / have written permission to scrape — message me with proof first.
The site I want scraped has anti-bot protection. Can you get around it?
I respect rate limits and use realistic browser headers, but I won't actively bypass CAPTCHAs, IP-blocking, or fingerprinting systems. If a site is actively blocking scrapers, that's a strong signal not to scrape it.
Will my data stay private?
Yes — I never share or reuse client files or scraping results. NDA available on request.
Can I run the scraper myself afterwards?
Premium includes the Python script with a README. You'll need Python 3.10+ and 5 minutes to set up.
Can you scrape recurring (daily / weekly) and email me the results?
Premium includes scheduling instructions. For full managed scraping (I host and email you results), message me for a custom offer.