Browse categories
Explore
Fiverr Pro
English
$
USD



Generic ChatGPT wrappers fail at scale. You need custom ai integration anchored to your private data.
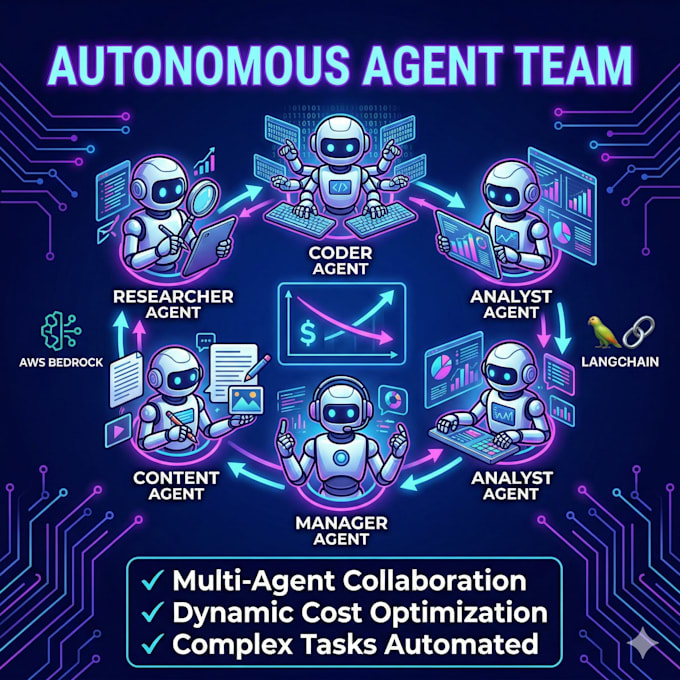
As a Full Stack AI Engineer, I architect advanced Python AI infrastructures. I bypass basic scripts to build complex LLM Integration ecosystems. Whether you need a SaaS backend or a bespoke RAG pipeline for semantic search, I develop custom AI agents for multi-step reasoning.
Architectural Deliverables:
The Engineering Advantage:
Message me your requirements. Lets architect your AI system today.
Full Stack AI Engineer
Languages
How do you ensure my company data stays secure during AI integration?
I architect secure Python backends with isolated vector DBs (Milvus/PostgreSQL). Data is processed via enterprise-grade APIs (AWS Bedrock, Anthropic) with strict zero-retention policies, ensuring your proprietary data never trains public models.
Can you prevent the AI agent from hallucinating or making up facts?
Yes. I engineer advanced RAG pipelines using semantic search and vector databases. This restricts the LLM to only synthesize answers from your injected company documents, completely eliminating hallucinations and guaranteeing factual outputs.
How do you connect the custom AI backend to my existing software?
As a Full Stack Engineer, I build robust FastAPI Python endpoints that seamlessly connect your new AI agents to any frontend (Next.js, React) or existing SaaS platform. You receive fully documented, production-ready APIs for immediate deployment.
How do we manage API costs when scaling multi-agent systems?
I deploy LiteLLM Server and OpenRouter within your architecture. This enables dynamic model routing—automatically switching between GPT-4, Claude, or Llama based on task complexity—maximizing inference performance while drastically reducing API costs.
Do I own the source code and the AI infrastructure after delivery?
Absolutely. I deliver fully documented Python code and system architecture. Whether hosted on AWS Bedrock or custom cloud servers, you retain 100% ownership and control over your proprietary AI pipeline, agents, and integration endpoints.