Browse categories
Explore
Fiverr Pro
English
$
USD
Big data engineer
Level 2
Has met high performance criteria and has a proven track record for meeting client expectations.
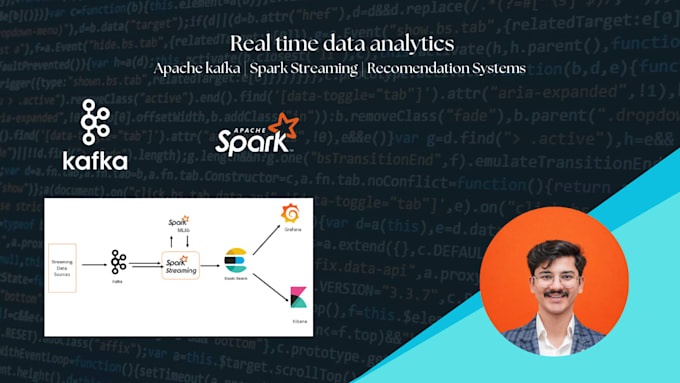
Modern applications generate massive real-time data streams from websites, mobile apps, IoT devices, and cloud platforms. Processing this data efficiently requires scalable streaming architectures and reliable data pipelines.
I am a Data Engineer specializing in big data systems and real-time processing, and I will help you design and implement high-performance streaming pipelines using technologies like Apache Kafka and Apache Spark.
I have experience building distributed data systems and large-scale analytics pipelines, including a real-time music recommendation system that processed 100GB+ of streaming data using Hadoop and Spark, and real-time ETL pipelines with data warehousing for enterprise analytics.
Technologies
Example Use Cases
I focus on building scalable, reliable, and production-ready streaming pipelines that turn live data into actionable insights.
Contact me before placing an order to discuss your requirements.