Browse categories
Explore
Fiverr Pro
English
$
USD
Transforming your ideas into solutions, websites and digital growth!
IS YOUR DATA STUCK IN THE PAST? ITS TIME TO GO REAL
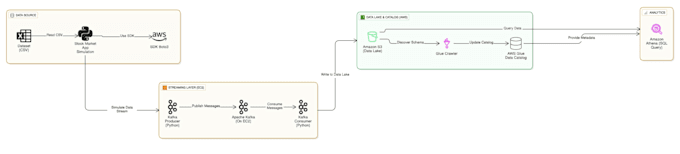
I am a specialized Cloud Data Engineer experienced in building high-performance data architectures. I recently engineered a Real-Time Stock Market Streaming Pipeline capable of handling massive data volatility using Apache Kafka and AWS, and I will build this same enterprise-grade quality for your business.
My Technical Stack:
What I Will Build For You:
Why Choose Me? Unlike generic developers, I understand Financial Data. My code is modular, well-documented, and ready for production.
️
PLEASE MESSAGE ME BEFORE ORDERING to discuss your specific architecture needs!

Tools & Platforms:
AWS Glue DataBrew
•
Kafka Connect
•
Apache NiFi
Do I need to provide my own AWS account credentials?
Yes. For me to deploy the pipeline, I will need an IAM User with appropriate permissions (S3, EC2, Redshift access). I can guide you on how to create this securely without sharing your root password
Will running this pipeline be expensive on my AWS bill?
I design for cost-efficiency. I use "Free Tier" eligible resources (like t2.micro instances for Kafka) where possible and configure S3 Lifecycle policies to archive old data, keeping your running costs low.
Do you offer support if the pipeline breaks after delivery?
Yes. The Standard and Premium packages include a post-delivery support window (5-7 days) to fix any bugs related to my code. I also provide a guide on how to restart services if they stop.
Which API do you use for fetching stock market data?
I typically use yfinance or Alpha Vantage for real-time simulation. However, the pipeline is modular. I can swap the "Producer" script to ingest data from any financial API you prefer (eg Polygon.io or IEX Cloud).
How do you handle high volatility or data spikes in the market?
The architecture uses Apache Kafka as a buffer. If the stock market sends a massive spike of data, Kafka queues it safely until the consumers (Spark/Python) can process it, ensuring no data is lost during high traffic.
Why do you use Zookeeper in this architecture?
Zookeeper manages the Kafka brokers. It tracks the status of the Kafka nodes and keeps track of which topics and partitions are active. It is essential for the fault tolerance of the streaming cluster.
How "real-time" is the data processing?
The latency is extremely low. The Kafka Producer fetches stock prices instantly, and the Consumer processes them in near real-time (usually within milliseconds to a few seconds), making it suitable for live dashboards.
What format do you save the data in S3?
generally save data in Parquet or CSV format. Parquet is highly recommended for financial data because it is compressed and columnar, which makes querying it via AWS Athena or Redshift much faster and cheaper.
Does this pipeline handle duplicate data?
Yes. I implement logic in the Consumer script (using Spark or Python Pandas) to drop duplicates based on timestamps and Stock IDs before loading the final clean data into your database.
Can I connect this pipeline to a dashboard like PowerBI or Tableau?
Absolutely. Since the final data lands in AWS Redshift or S3, you can directly connect PowerBI, Tableau, or AWS QuickSight to visualize the live stock trends.