Browse categories
Explore
Fiverr Pro
English
$
USD
I am a Senior Data Engineer with 6+ years of experience designing scalable data pipelines and cloud data platforms. I specialize in building reliable ETL workflows, transforming raw data into structured datasets, and enabling analytics-ready data systems.
I can help you with:
-ETL pipeline development using Python, SQL, and PySpark
-Data ingestion from APIs, files, and databases
-Data transformation and optimization
-Cloud data pipelines using AWS (S3, EMR, Redshift, Glue, Kinesis,Athena)
-Lakehouse architecture (Bronze, Silver, Gold layers)
-Data warehouse integration and performance tuning
I focus on building efficient, scalable, and production-ready data pipelines that support analytics, reporting, and machine learning workflows.
If you need help designing or improving your data pipeline or data platform, feel free to reach out before placing an order.

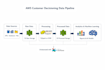
Warehouse Platform:
Snowflake
•
Redshift
•
PostgreSQL / Greenplum
Project Type:
New Build
