Browse categories
Explore
Fiverr Pro
English
$
USD
About Me
Hi! I'm Sivanandham, a Machine Learning Specialist with a proven background in financial forecasting, stock market prediction, and data-driven automation. With over 2 years of hands-on experience in Artificial Intelligence, Machine Learning, Data Analysis, Data Science and AI systems.
I have delivered 25+ real-world ML projects that actually solved business problems not just academic demos
Services I Offer:
ML Model Development: Classification, Regression
Pipeline Steps: Data ingestion, Data Cleaning & Preprocessing, Feature engineering, Model Training, Hyperparameter Tuning, Validation & Prediction
Model Training & Evaluation: Accuracy, F1-Score, ROC-AUC
Model Optimization: Evaluation metrics, GridSearchCV
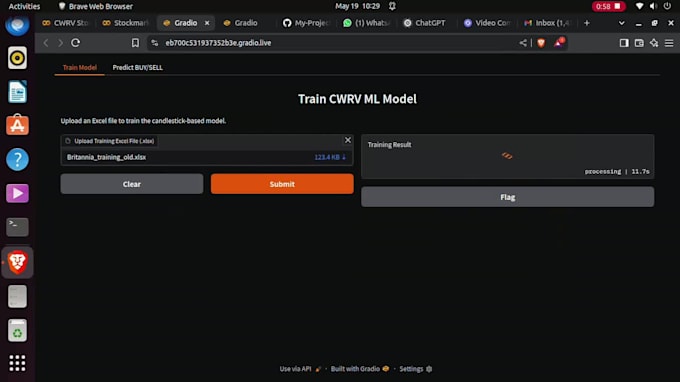
Model Deployment: Gradio-based apps, local deployment
Tools & Technologies:
Languages & Libraries: Python, Pandas, NumPy, Matplotlib, Seaborn, Gradio, Excel, Scikit learn
ML Algorithms: Decision Trees, Support Vector Machine(SVM), Logistic/Linear Regression, Gradient Boosting, Cross-Validation, Grid Search
Version Control: GitHub
Tip: Before placing an order, message me with your dataset, goals and expectation so I provide the right plan and timeline for you




Programming language:
Python
•
Colab
Frameworks:
Scikit-learn
•
PyTorch
•
Panda
APIs:
Google Cloud Vision API
Tools:
Jupyter Notebook
•
OpenCV
•
Excel
•
MLflow
•
Colab
Can you work with my raw dataset, or should it be clean?
Yes, I can work with raw data. I offer complete data cleaning (ETL), preprocessing, and transformation to make your dataset ML-ready — including handling missing values, outliers, and formatting issues
What deliverables will I receive?
You’ll receive Python code (clean and well-commented), performance visuals (confusion matrix, ROC curve, feature importance), model explanation, and deployment-ready files
How do you ensure the model performs well?
I use proven techniques like cross-validation, train-test split, bias-variance analysis, and hyperparameter tuning (GridSearchCV) to build optimized and robust models.
How do I choose between Basic, Standard, and Advanced packages?
● Basic is great for simple use-cases or beginner learning. ● Standard includes full preprocessing, imbalance handling, and tuning, — ideal for small businesses. ● Advanced offers production-ready models, multiple algorithm comparison, and UI perfect for professionals and research projects.
Will my data be kept private?
Absolutely. Your data is treated as confidential and will never be shared or reused.
How do I know your service is reliable?
With 25+ real-world ML projects, advanced training (6-month AI certification from Novi Tech), and proven business results (e.g., 2166% growth using ML insights), I deliver structured, explainable, and impactful models tailored to your goals.
Can you provide documentation or notebook-style explanation?
Yes. I can deliver the project in a Jupyter Notebook format or Google Colab with step-by-step explanations, comments, and visual outputs for better understanding and reuse.
What size of dataset can you handle?
I can work with small to moderate datasets efficiently custom offers can be made to ensure optimized performance using efficient memory handling techniques.
What specific data science services do you offer?
I provide a range of services including data cleaning and preprocessing, exploratory data analysis, predictive modeling, fine tuning, machine learning algorithm development, data visualization, and actionable insights.
How do you ensure the confidentiality and security of my data?
Your data is handled with strict confidentiality. All sensitive data is processed in secure environments and will not be uploaded online or processed using online platforms: your data is accessible only to you and the Jupyter Notebook running on my laptop.