Browse categories
Explore
Fiverr Pro
English
$
USD
Do you have a dataset that's full of missing values, duplicates, outliers, or inconsistent text? I can help you turn that messy file into a clean, reliable dataset that's ready for analysis or machine learning.
I use Python and Pandas to apply a structured cleaning process that covers:
Filling or removing missing values with sensible strategies (median for numbers, Unknown for noncritical text, dropping rows for critical fields).
Removing duplicate records to keep your data accurate.
Detecting and handling outliers so your results aren't skewed.
Fixing text issues such as empty strings, HTML tags, and inconsistent formatting.
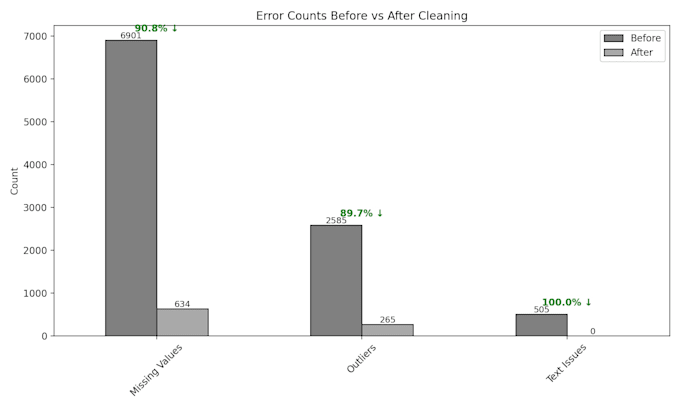
Providing a clear before and after summary so you can see exactly what was improved.
What you'll receive:




What file formats do you accept?
I can work with CSV, Excel, or text‑based datasets. If your data is in another format, let me know and I’ll confirm if it can be converted
How will I know my data has been cleaned?
I provide a before‑and‑after summary showing the number of missing values, duplicates, outliers, and text issues. You’ll see exactly what was fixed
Can you handle large datasets?
Yes. My packages cover up to 10,000 rows, but I can create a custom offer for larger files.
Do you provide visualizations?
Yes, I can include charts such as histograms or boxplots to show improvements. This is available as an extra service.
Will you share the cleaning process?
If requested, I can deliver the Colab/Jupyter notebook with all the functions I used, so you can reuse the pipeline on future datasets.
What if I need the work faster?
I offer extra fast delivery options. You can choose 24‑hour or 48‑hour turnaround depending on the package.